A report by Gartner estimated that unstructured data represents 80 to 90% of all new enterprise data. Eighty to ninety percent! If that isn’t significant enough, it is growing three times faster than structured data. An even bigger surprise is that only 18% of organizations take advantage of unstructured data. The competitive advantage of utilizing information your competitors aren’t is significant. Here are the pros and cons of structured versus unstructured data sets. Integrate.io summarized the difference between structured versus unstructured data sets very clearly.
Structured Data
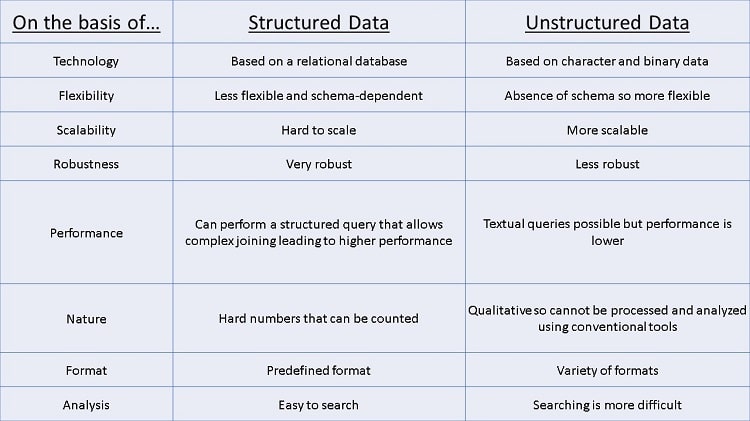
Structured data, often referred to as quantitative data, is highly organized and easily decipherable. Structured Query Language (SQL), developed by IBM way back in 1974, is the programming language almost universally used to manage structured data. It makes it easy for business user to quickly input, search and manipulate this type of data. The architecture of structured data makes machine learning algorithms particularly easy to use. Users don’t have to have an in-depth understanding of different types of data and how they function to effectively access and interpret the data, and since it has been around much longer there are many more tools to analyze.
The problems with structured data include limited flexibility and scalability, due to its predefined structure, and limited storage options. The use of data warehouses limits changes in the data requirements without a significant expenditure of time and resources.
Unstructured Data
Unstructured data, commonly called qualitative data, cannot be processed and analyzed via conventional methods. With no predefined data model, it is best managed in non-relational (NoSQL) databases. Data lakes are also used to preserve this data in raw form. Unstructured data includes text, mobile activity, social media posts and IoT data to name a few. When this data is stored in its ‘native format’ or undefined until needed, it enables data scientists to prepare and analyze only the data they need. Since there is no pre-defined format the data is collected quickly, easily and at pay-as-you-use pricing cuts cost and increases scalability.
The reason more firms aren’t taking advantage of this great trove of information about their products or services is due to its this very undefined, unformatted nature. Unspecialized business users don’t fully understand the specialization needed by a data scientist to make this data useful, and the tools and methods to do so are still being developed.
To take advantage of unstructured data companies have to rebuild their architecture, refactor applications and use third-party data movement packages. The transition is difficult because legacy file systems don’t make it easy. The genome research that was used to develop the COVID-19 vaccine came from innovations on unstructured data. More organizations need to progress from structured data to unstructured data sets to bring their innovations to life.

