The Dice 2020 Tech Job Report said data engineer was the fastest growing job in technology with a 50% year-over-year growth in the number of open positions. Quanthub.com reports that demand for data engineers has outstripped supply since about 2016. Yet demand for data scientists seems to be all company’s talk about. Yet data engineers are more in demand than data scientists.
The easy answer for why data engineers are more in demand than data scientists is a four letter word, data. Around 2011 the term data engineer started to crop up in job titles for new data-driven companies like Facebook and AirBnB. The volume, variety and velocity of big data was pushing a vast array of technological changes. As big data grew the skill sets of software engineers, SQL developers or existing IT professionals weren’t meeting the needs of a type of software engineering focused deeply on data. Data infrastructure, data warehousing, data mining, data modeling, data crunching and metadata management were all becoming minimum requirements to support a data science strategy.
In 2019 the CTO of IBM said that 87% of data science projects never make it into production. Gartner predicts 80% of data science projects fail. It took some time for the market to recognize that a data scientist could not do it all. Data engineers are needed to figure out the core foundation on how the data is organized and structured in the data warehouse. Data Scientists are the internal clients of the data engineers. They depend on the engineers to provide them with reliable and useful data. Data Scientists are highly skilled in math and statistics, R, algorithms and machine learning techniques. Data engineers must be well versed in SQL, MySQL, NoSQL, architecture and cloud technologies and frameworks such as agile and scrum. Both positions will probably know Python or other coding languages in common and visualization techniques.
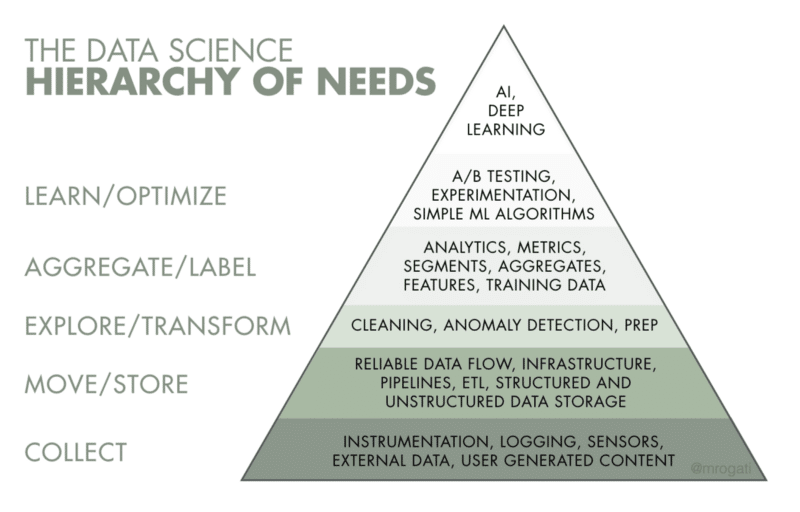
Data Collective Equity Partner, Monica Rogati, created the data science hierarchy of needs shown above. Bias or devaluation of the data engineering role began with a belief that they focused most of their attention on the “collect” building block of this hierarchy. They were simply collectors of data. For non-technical staff this was the easiest to understand. Data engineers really spend their time and drive their value at the second and third level. They take the rivers of data from multiple sources and channel it into usable pipelines. Their skills are sophisticated and constantly requiring updating and flexibility.
Why then are Data Engineers so hard to hire?
Compensation
Because of the over-simplification of what they do in non-technical minds, compensation hasn’t kept pace with the sophisticated skill set data engineers need and are offering. Glassdoor.com says the median salary for data engineers is $102K with the average salary at $138K. We consistently see clients trying to hire data engineers at the $100K level. They don’t succeed. Firms willing to pay $130K+ are successful.
Pedigree
Engineers and IT professionals are often not mainstream candidates. Often the best programmers are self taught and have better skills than someone with an a-lister pedigree, yet they are eliminated in the hiring process before they even get to someone who can assess their technical skills. Requiring the right pedigree eliminates probably 1/3 of potential candidates.
Coolness
Because of the general perception of data engineers as data processors and data scientists as leading the Data Science function, candidates hesitate taking a position that isn’t clearly defined. Data engineers are highly driven by job content and the opportunity to do cool projects. Addressing this need with bonuses, flexible work schedules, important job titles and good placement on the reporting hierarchy, recognition and fast track career development will keep the best data engineers at your firm doing their best work.

